

现代web开发中,在数据库和应用程序服务器之间使用缓存是常见的手段,它有效的减轻了后端数据库服务器的压力。结构化数据库中的数据是按照表、字段这种结构存储的,而作为缓存系统的memcached或是redis-server是以key-value的方式存储数据的。如何将结构化的数据存储到非结构化的缓存系统是一个问题,对于MySQL等结构化数据库我们可以按照以下方式存储。
首先,对于表中单条数据我们可以按照Bean存储在缓存中,key为“表名+id”,value为Bean对象。
然后,对于列表查询,我们可以使用“select id from article where status=1 limit 10”这种语句查出article表的id列表 List<Long> 。然后通过id从缓存中逐条加载 Bean ,最终形成我们需要的 List<Bean>。而我们可以将通过sql查出来的List<Long>结构的id数组作为一个缓存对象,其key可以按照某种规则生成,例如“方法名+override_index+参数...”。
上面说的两种数据对象的存储方式都没有问题,而其中的难点在于如何管理缓存,我们知道,一个列表查询的结果List<Long>在这张表发生增删改的时候都会发生变化,因此,详细来说我们应该在列表的某个字段发生增删改的时候清理掉这个id列表缓存,等下次查询的时候再自动重建新的缓存,以保证缓存的正确性。不过,若是联表查询呢?联表查询“select user.id from article, user where article.userid=user.id and article.status=1”查出的是一个id列表,我们将其缓存假设key为key1,但是一旦article表和user表其中之一发生增删改,那么这个缓存数据应当失效,也就是说,Article在进行 Update()、Save()、Delete() 的时候我们应该清理掉这个key为key1的缓存,同样对于User在进行 Update()、Save()、Delete() 的时候我们也应当清理掉 key1 的缓存。在这儿只是列举了两个表联查,并且只是提到了一个联表查询,假如有N个表联表,而且有M个联表查询语句那么我们应该在多少个方法中调用清理这种缓存的方法呢M*N*3,好多好麻烦呀。
为了管理list的缓存,定义一个树形结构如下
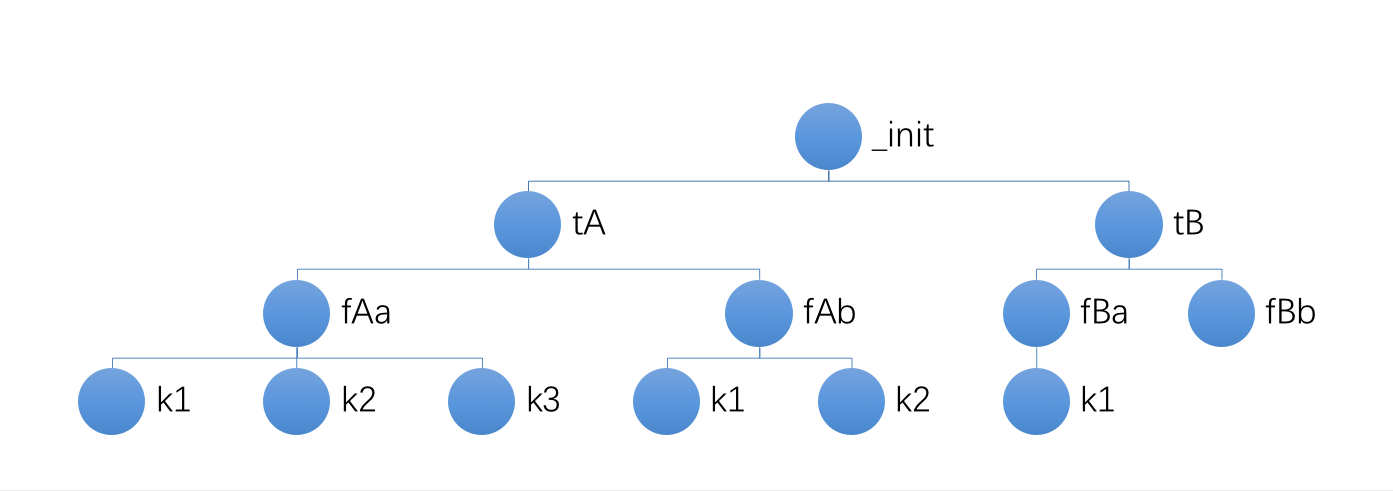
t开头的节点表示表名,tA、tB 表示 A 表和 B 表,f开头的表示字段,fAa 表示 A 表 a 字段,fAb 表示 A 表 b 字段,k开头的表示列表的缓存键。这个数据结构表达了我们应该如何清理缓存,比如A表中的a字段发生的改变(增删改),那么我应该清理掉键名为k1, k2, k3的缓存,A表字段b发生增删改时应该清理掉键名为k1, k2的缓存,B表a字段发生增删改时应该清理掉键名为 k1 的缓存。然后将该树形结构拆分为三级,分别用三类的key-value存储起来就好,也不必担心结构过于庞大,上图可以拆为6个key-value:
[0] _init->(tA, tB) [1] tA->(fAa, fAb) [1] tB->(fBa, fBb) [2] fAa->(k1, k2, k3) [2] fAb->(k1, k2) [2] fBa->(k1)
上图的结构来自于如下三个SQL查询
[K1] select id from A, B where A.fAa = ? and A.fAb = ? and B.fBa = ? ... [K2] select id from A where A.fAa = ? and A.fAb = ? ... [K3] select id from A where A.fAa = ? ...
 粤ICP备2022112217号
粤ICP备2022112217号