

之前在做 Goj 项目的时候执行服务器部分使用 go 语言 kill 进程,发现无法 kill 该进程的子进程,后来发现貌似别的语言也无法直接 kill 掉当前进程的子进程链。kill 子进程链的应用场景是这样的,我在做 judger服务器的时候发现我调用 gcc 编译源码会在某些极端的情况下卡死,然后卡死后我需要 kill 掉 gcc 的进程,我使用 go 语言的相关 api kill 掉 gcc (因为我拿得到 gcc 的进程 id),然而,我发现 gcc 会调用别的命令,记忆中貌似是一个叫做 ar 的命令,实际上是这个子进程卡死了,于是我 kill 掉身为父进程的 gcc 之后,它的子进程依然存在,变成了孤儿进程,继续卡着。但是我没有 api 可以拿到 gcc 卡死的子进程的进程 id,所以我也无法 kill 掉它。我当时的临时解决方案是调用 killall 命令去按照名称杀掉它。
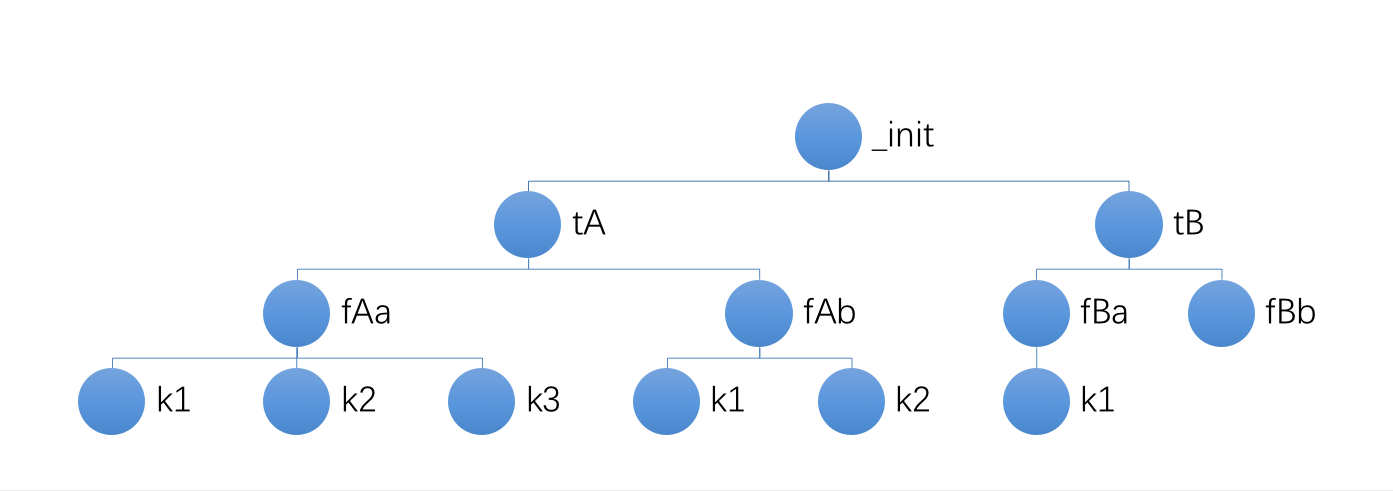
之后一次在某个群里提到这件事情,随口问了一句如何获取某个进程的子进程,linux api 中是没有这种 api 的,一位同学提醒了我,你可以从 /proc 目录中查。今天我用 go 语言实现了它,linux 系统中 /proc 目录记录了所有的进程信息,但是这些信息中依然没有记录某个信息的子进程,不过它记录了某个进程的父进程,于是我遍历了 /proc 目录中的所有进程的进程信息,然后根据进程的父代关系构成了一颗进程树,这颗树的顶端必定是 init 进程,于是,我便可以从这颗进程树上从上往下搜索查找出某个进程的子进程了。这样一来,一个简单的进程树便可以让我轻松的查找出某进程的子进程,同样也可以 kill 掉某颗进程树,将当前进程及其子进程 kill 掉已经不再是一件难事了。
如果你对此感兴趣,欢迎参阅源码 https://github.com/gojudge/proc
最后,我要说明的一点是:世界上没有什么事情是一棵树解决不了的,如果有,那么两颗树一定能够解决。
 粤ICP备2022112217号
粤ICP备2022112217号