

现在的许都网站都使用MVC构架,为了应对高并发,人们通常使用基于内存存取的Cache系统作为后端减压的应对方式。在网站的后端,主要涉及业务逻辑处理和数据库查询,而数据查询许多时候在高并发的状况下成为了性能的瓶颈。本文要讨论的是Cache如何使用才能够更加合理,更加有效。
网站的MVC构架通常情况如下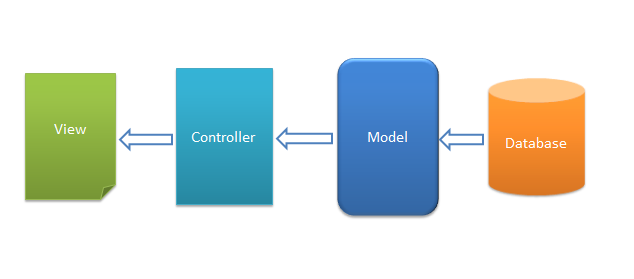
数据库(Database)处于最后端,其次是Model层,Model层是对数据库直接操作的一种封装,然后是Controller层,Controller层是专门处理业务逻辑的,获取数据是直接调用Model层中封装的各种方法,最外层是View层,负责显示数据到页面,Controller层处理完毕的的数据传到View层,由其渲染为静态页发送给用户浏览器。
构想一,将Cache用于Model层中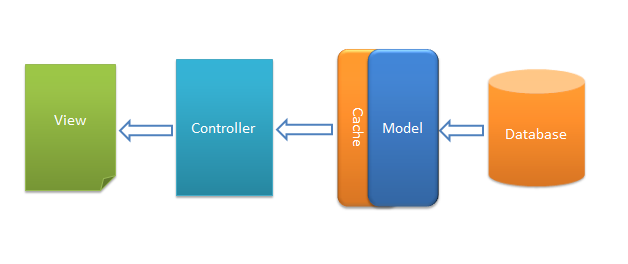
Cache用于Model层是将查询到的数据放置到Cache中,从而避免下次同样的数据需要再次去数据库执行SQL语句查询,而是直接从Cache中更快的读取数据(理论上某些SQL查询非常耗时,这样Cache效果更明显)。
// 通过id获取文章-cached
func GetArticle(id int) (Article, error) {
var err error
var art Article
cache := config.GetCache("GetArticle.id." + fmt.Sprintf("%d", id))
if cache != nil { // check cache
json.Unmarshal([]byte(cache.(string)), &art)
return art, nil
} else {
o := orm.NewOrm()
o.Using("default")
art = Article{Id: id}
err = o.Read(&art, "id")
data, _ := utils.JsonEncode(art)
config.SetCache("GetArticle.id."+fmt.Sprintf("%d", id), data, 600)
}
return art, err
}构想二,将Cache用于Controller层,甚至View层。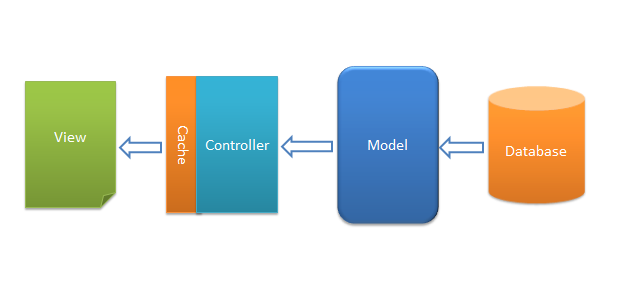
若是将Cache用于Controller层,可以同时减轻业务逻辑处理和数据库查询。如果将Cache用于View层,甚至可以减轻模版的渲染工作,这样一来有点类似于全站静态化的感觉了,但是我并不觉得这是一个好方法,或许对于个别网站是可行的,但是对于大多数相对复杂的网站,这是完全不科学的方法。例如,一个论坛网站,某个页面有帖子正文,有回复,若是将这种页面放入Cache势必会导致不得不降低Cache过期时间,而最终的结果将会是Cache命中率极低,还不如不用Cache。
对于我来说,我更偏向于在Model层使用Cache,因为这样会更加灵活能够定向的缓存该缓存的东西,而不是像方案二中外层的缓存使得数据块不易分离。

 粤ICP备2022112217号
粤ICP备2022112217号